
선거의 계절이 되면 언론에서는 각종 여론조사 결과를 발표한다. 이 결과들을 보면 오차 +-2% 신뢰도 95%와 같은 표현을 볼 수 있다. 오차는 무슨 뜻인지 알 수 있는데, 신뢰도는 무슨 뜻일까? 믿을 수 있는 정도라니?
이 세상 많은 일들이 정규분포를 따른다. 따라서 많은 자료들 평균 주변에 대부분 몰려있게 되고, 정규분포의 평균과 분산을 안다면 그 ‘몰려있는 정도’를 계산하여 구할 수 있다. 예를 들어, 평균이 m, 표준편차가 σ인 정규분포를 따르는 자료가 m-σ와 m+σ 사이에 나타날 확률은 약 68% 정도이다. 반대로 이 구간을 벗어날 확률은 약 32% 정도가 된다. 평균을 중심으로 한 구간이 크면 클수록 자료가 이 구간에 나타날 확률은 더욱 커진다. 반대로 이 구간을 벗어날 확률은 급격히 작아진다.
여기서 잠깐 정규분포에 따른 확률을 어떻게 계산하는지 알아보자. 예를 들어 m-σ와 m+σ 사이의 확률을 계산하려면 다음 적분의 값을 구하면 된다.
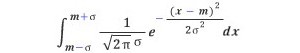
적당히 변수를 변환하면, 이 적분은  에 대한 것으로 고칠 수 있다. 이 함수의 부정적분을 구할 수만 있다면 일은 간단한데, 수많은 수학자들이 연구를 거듭하여도 도무지 그 부정적분을 x에 대한 사칙연산, 삼각함수, 지수함수, 로그함수, 역삼각함수 등등 잘 아는 함수들로는 - 이런 함수를 초등함수라 한다 - 나타낼 수가 없었다. 이 난제는 프랑스 수학자 리우빌(J. Liouville)이 1835년에 이 부정적분이 초등함수로는 표현되지 않음을 증명하여 비로소 해결(?)되었다.
에 대한 것으로 고칠 수 있다. 이 함수의 부정적분을 구할 수만 있다면 일은 간단한데, 수많은 수학자들이 연구를 거듭하여도 도무지 그 부정적분을 x에 대한 사칙연산, 삼각함수, 지수함수, 로그함수, 역삼각함수 등등 잘 아는 함수들로는 - 이런 함수를 초등함수라 한다 - 나타낼 수가 없었다. 이 난제는 프랑스 수학자 리우빌(J. Liouville)이 1835년에 이 부정적분이 초등함수로는 표현되지 않음을 증명하여 비로소 해결(?)되었다.
결국 정규분포처럼 부정적분이 간단히 표현되지 않는 함수의 적분을 계산하려면, 적분하려는 함수가 그리는 곡선 아래 부분의 넓이에 대한 근삿값을 직접 구하는 방법밖에 없다. 고등학교 수학 교과서 제일 뒤에 실려 있는 정규분포에 대한 표가 바로 이 근삿값들을 일정 구간마다 일일이 구해서 만들어놓은 것이다.
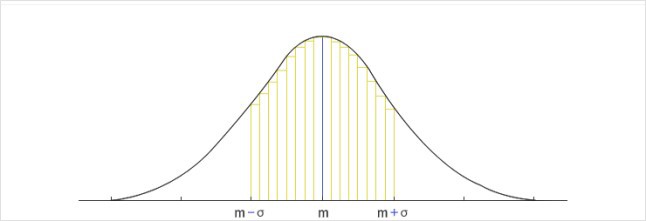
정규분포의 개념에 도달하기까지 오랜 시간과 노력이 필요하였지만, 일단 이 분포를 이해하고 나자 이제 반대 방향으로 생각할 수 있게 되었다. 즉, 평균과 표준편차를 아는 상태에서 자료의 상태를 살피는 것이 아니라, 자료의 상태로부터 평균과 표준편차를 거꾸로 추측하는 것이 가능해진 것이다.
어떤 관측 결과로부터 참값이 얼마인지 정확하게 알아내는 것은, 오차를 생각하면 당연히 불가능한 일이다. 그러나 그 관측 결과가 정규분포를 따른다는 것을 알면, 참값의 정확한 값은 몰라도 그 값이 대략 어느 정도 되는지는 알 수 있다. 다만 그 추정이 틀릴 가능성이 어느 정도는 있다는 사실은 명확히 해두어야 한다.
어떤 물체의 길이를 잰 결과 대부분의 값은 1미터 정도였다고 하자. 이로부터 틀릴 가능성이 없는 추정을 한다면, 그 길이가 0미터보다는 크고 2미터보다는 작다고 하면 충분할 것이다. 사실 수학자들은 늘 최악의 상황을 걱정하는 사람들이어서, 만약 절대로 틀릴 리가 없는 범위를 구하라고 하면 아마도 “길이는 유한하다”라고 답할 것이다. 길이가 0미터보다는 크지만 어떤 값보다 작을지는 알 수 없다는 말이다. 그러나 이런 식의 추정은 전혀 무의미하므로, 어떻게든 범위를 좁혀서 말할 필요가 있다.
일상적으로야 ‘대충 1미터 정도’라는 표현으로 충분하지만, 실제로는 0.999미터인데 관측 오차 때문에 1미터가 될 가능성이 어느 정도인지를 알 수 있다면 훨씬 유용할 것이다. 바로 여기에 정규분포가 사용된다. 관측 횟수가 n이고 관측 결과의 평균이 M이라면, n번씩 관측할 때마다 얻어지는 평균값 M들의 값은 당연히 참값에 매우 가깝다. 관측 횟수가 많아지면 많아질수록 평균값이 참값에 더욱 가까워지는 것 또한 당연하다. 더욱 가까워진다는 것은 M들의 표준편차가 작다는 뜻이 되는데, 관측 결과 하나하나가 표준편차 σ인 정규분포를 따른다면, n번 관측하여 얻어지는 M의 표준편차는 다음과 같이 된다.

관측이라는 게 원래 그렇지만, 평균값 M이 정확히 참값이 되는 경우도 있고 참값에 미치지 못하는 경우도 있고 참값을 넘는 경우도 있다. 그러나 이런 M들로 가능한 값을 모두 구하여 전체의 평균값을 구한다면 그 값은 참값이 될 수밖에 없다. 따라서 참값이 m미터라면 관측 결과의 평균 M은 평균이 m이고 표준편차가σ/√n인 정규분포를 따르게 된다. 위의 정규분포 그래프를 보면 다음의 사실을 알 수 있다.
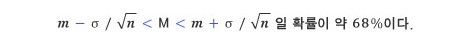
위 식에서σ/√n를 이항하면, 아래와 같은 결과가 나온다.
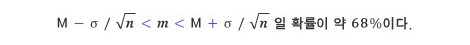
다시 말해, 참값 m이 관측으로 구한 평균값 M 근처에 있을 확률을 말할 수 있게 된 것이다.
다만, 이 방법에 한 가지 문제가 있으니, 전체 자료를 알아야 구할 수 있는 표준편차를 주어진 관측 결과로부터 알아내야 한다는 점이다. 당연히 정확한 표준편차를 알 수는 없으므로, 여러 가지 방법으로 원래의 표준편차를 대신할 수 있는 값을현재의 자료로부터 구하게 된다. 그 가운데 한 가지 방법은 관측 자료들 자체의 표준편차를 사용하는 것이다. 자료의 양이 충분히 많다면, 자료 하나하나가 흩어져 있는 양상이 정규분포를 따르기 때문에 이와 같은 생각은 매우 자연스럽다.
한편 위의 예에서는 확률 68%를 신뢰도라 하며, 100%에서 이 신뢰도를 뺀 값 32%를 유의수준이라 한다. 뭔가 결과가 나오기는 했지만, 잘못될 가능성에 유의해야 하는 정도라는 뜻이다. 잘못된 가능성이 32%라는 것은 너무 큰 값이므로, 보통은 신뢰도 95% (유의수준 5%)나 신뢰도 99% (유의수준 1%)를 기준으로 생각한다. 아래의 구간이 대략 각각 신뢰도 95%와 99%의 구간이다. 이런 구간을 ‘정해진 신뢰도를 주는 구간’이라는 뜻에서 신뢰구간이라고 한다.
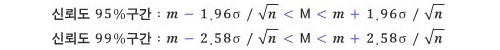
여론을 완벽하게 알려면 모든 사람을 대상으로 설문 조사를 하는 것이 최선이다. 그러나 실제로 모든 사람을 조사하기는 대단히 어려워서, 대개는 표본으로 몇 명에 대해 조사한 다음 전체의 결과로 추정하는 것이 보통이다. 이것 역시 정규분포를 이용한 추정과 같은 방식으로 이루어진다.
어떤 여론조사에서 1000명 가운데 189명이 후보 A를 지지했다고 하자. 이때, 이 후보의 지지율이 정확히 18.9%라고 할 수 있을까? 실제 지지율은 거의 0%이면서 용케도 후보 A를 지지하는 사람을 긁어 모아 18.9%라는 비율이 나올 수도 있고, 반대로 실제 지지율은 거의 100%인데도 후보 A를 지지하지 않는 사람 위주로 악의적으로 조사 대상을 선정했을 가능성도 없지는 않다. 그러나 이런 여론조사는 전혀 무의미하므로, 불특정다수를 선정하여 조사를 진행하게 된다. 이 경우 18.9%라는 지지율은 실제로는 18% 정도인데 우연히도 후보 A의 지지자가 조금 더 선정되어 나온 결과일 수도 있고, 실제 지지율은 20%인데 우연히도 후보 A의 반대자가 조금 더 선정되어 나온 결과일 수도 있다.
이렇게 실제와 다른 결과가 우연히 일어날 확률을 구할 수 있다면, 후보의 실제 지지율을 짐작하는 데에 큰 도움이 될 것이고, 이를 바탕으로 선거전략을 수정할 수도 있다. 후보 A에 대한 실제 지지율을 x라 하면, 이것은 전체 유권자에 대한 지지자의 비율이 x라는 뜻이다. 이제 관점을 살짝 바꾸어, 모든 사람이 후보 A를 비율 x 만큼 지지하고 있다고 하자. 이렇게 생각하면, 위의 1000명에 대한 여론조사는 후보 A가 x만큼의비율로 나오는 동전 1000개를 던지는 것과 마찬가지로 생각할 수 있다. 즉, 일어날 확률이 x인 사건을 1000번 시행하는 이항분포가 된다. 이 분포는 시행횟수가 충분히 많으므로 아래와 같이 생각할 수 있다.
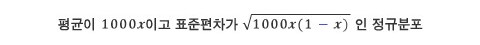
실제 지지율이 x이므로 여론조사에서는 대략 1000x 명이 후보 A를 지지할 것이다. 그러나 여러 우연적인 요소로 인해 단 한 명의 오차도 없이 정확히 1000x = 189로 딱 맞아 떨어지는 경우는 극히 드물다. 대신에 구간을 정하여 179명에서 199명 사이의 사람이 후보 A를 지지할 것이라고 한다면 이것은 확률이 훨씬 높아 보인다. 구간이 넓어질수록 확률은 더 커진다. 이 여론조사를 정규분포로 생각할 수 있으므로, 신뢰도 95%인 구간을 생각하여 보면, 다음 부등식이 된다.

이제 이 부등식을 x에 대하여 풀면, 여론조사의 결과로부터 실제 지지율이 어느 정도인지를 95% 신뢰도로 추정한 것이 된다. 그 결과는 다음과 같다.
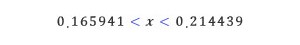
여론조사의 결과인 18.9 %와 비교하면 ±2.54%p 정도의 오차가 있는 셈이다. 바꿔 말하면, 실제 지지율과 여론조사의 결과인 18.9%의 차이가 2.54%보다 더 클 확률이 5% 정도라는 뜻이다. 사람에 따라서는 5%의 확률은 별것 아니라고 생각할 수도 있고, 반면 어떤 사람은 얼마든지 일어날 수 있는 확률이라고 생각하는 사람도 있다. 그에 따라 공약도 바뀌고, 선거 전략도 바뀌고, 심지어 사람이 바뀌기도 한다.
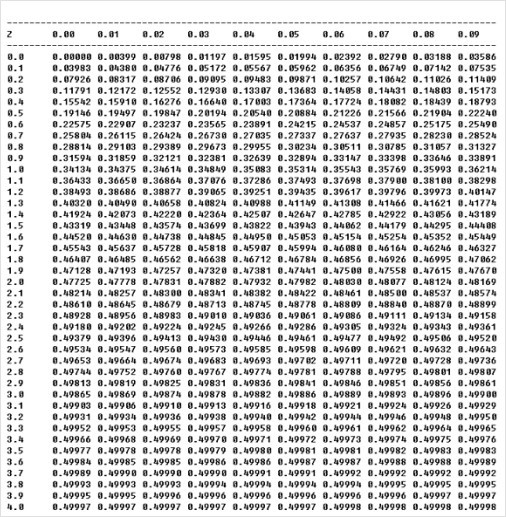
표준정규분포표
아래의 표는 정규분포곡선에서 0에서 Z까지의 확률을 표로 나타낸 것이다. 즉, 만일 Z=2.58의 값을 알고 싶다면 왼쪽 첫 열에서 2.5로 나타난 행을 찾고 첫 행에서 0.08으로 표시된 열을 찾도록 한다. 그 값은 0.49506으로 표시되어 있다.
'Statistics' 카테고리의 다른 글
| 정규분포 (펌) (0) | 2015.05.17 |
|---|---|
| 확률을 대하는 두 가지 관점 (펌) (0) | 2015.05.17 |
| 우도_Likelihood(펌) (0) | 2015.05.06 |
| MOOC 소개 (펌)_zeronova.kr (0) | 2015.05.06 |
| MOOC 데이터 사이언스 코스 리뷰 (펌) (1) | 2015.05.06 |
