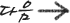Welcome!
# Load the cdc data frame into the workspace:
a <-load(url("http://assets.datacamp.com/course/dasi/cdc.Rdata"))
head(a)
dim(a)
str(a)
# The Behavioral Risk Factor Surveillance System (BRFSS) is an annual telephone survey of 350,000 people in the United States.
# As its name implies, the BRFSS is designed to identify risk factors in the adult population and report emerging health trends.
# For example, respondents are asked about their diet and weekly physical activity, their HIV/AIDS status, possible tobacco use, and even their level of healthcare coverage.
Which variables are you working with?
# The cdc data frame is already loaded into the workspace
# Print the names of the variables:
names(cdc)
Taking a peek at your data
# The cdc data frame is already loaded into the workspace
# Print the head and tails of the data frame:
head(cdc)
tail(cdc)
# http://www.cdc.gov/brfss/
# This function returns a vector of variable names in which each name corresponds to a question that was asked in the survey.
# For example, for genhlth, respondents were asked to evaluate their general health from excellent down to poor.
# The exerany variable indicates whether the respondent exercised in the past month (1) or did not (0).
# Likewise, hlthplan indicates whether the respondent had some form of health coverage.
# The smoke100 variable indicates whether the respondent had smoked at least 100 cigarettes in his lifetime.
Let's refresh
# The cdc data frame is already loaded into the workspace.
# View the head or tail of both the height and the genhlth variables:
head(cdc$height)
head(cdc$genhlth)
# Assign your sum here:
sum <- 84941 + 19686
# Assign your multiplication here:
mult <- 73 * 51
Turning info into knowledge - Numerical data
# The cdc data frame is already loaded into the workspace
mean(cdc$weight)
var(cdc$weight)
median(cdc$weight)
summary(cdc$weight)
Turning info into knowledge - Categorical data
# categorical data: look at absolute or relative frequency. (범주형 data는 빈도를 보는 것이 좋다)
# The cdc data frame is already loaded into the workspace.
# Create the frequency table here:
table(cdc$genhlth) # 빈도가 테이블 형태로 나온다
plot(cdc$genhlth) # 빈도가 히스토그램으로 나온다
# Create the relative frequency table here:
table(cdc$genhlth) / dim(cdc)[1] # dim()을 쓰면 row, column 수가 나온다
table(cdc$genhlth) / nrow(cdc) # nrow도 동일한 결과가 나온다
# dim(variable)[1] -> 행수
# dim(variable)[2] -> 열수
Creating your first barplot
# The cdc data frame is already loaded into the workspace.
# Draw the barplot:
table(cdc$smoke100) # 먼저 테이블로 표시
barplot(table(cdc$smoke100)) # x축이 2개의 값을 갖는 히스토그램으로 표시
# 먼저 table을 통해서 (0,1)로 묶어준다.
# 그다음 그래프를 그린다.
barplot(cdc$smoke100)
# 모든 row에 대해서 0,1이 섞여서 출력 되므로 black으로 보인다.
Even prettier: the Mosaic Plot
# The cdc data frame is already loaded into the workspace
gender_smokers <- table(cdc$gender,cdc$smoke100) # x,y의 분류축을 지정
# table의 축을 지정해 줄수 있다.
gender_smokers
# Plot the mosaicplot:
mosaicplot(gender_smokers)
# mosaicplot은 면적을 통해 가늠할수 있게 해 준다
Interlude: How R thinks about data (1)
# The cdc data frame is already loaded into the workspace
head(cdc)
cdc[1337,]
cdc[111,]
# Create the subsets:
height_1337 <- cdc[1337,5]
weight_111 <- cdc[111,6]
# Print the results:
height_1337
weight_111
Interlude (2)
# The cdc data frame is already loaded into the workspace
# Create the subsets:
first8 <- cdc[1:8, 3:5] # data table에서 특정한 영역만 선택
wt_gen_10_20 <- cdc[10:20 , 6:9]
# Print the subsets:
first8
wt_gen_10_20
Interlude (3)
# The cdc data frame is already loaded into the workspace
# Create the subsets:
resp205 <- cdc[205,]
ht_wt <- cdc[,5:6]
# Print the subsets:
resp205
head(ht_wt)
str(ht_wt)
Interlude (4)
# The cdc data frame is already loaded into the workspace
# Create the subsets:
resp1000_smk <- cdc$smoke100[1000]
first30_ht <- cdc$height[1:30]
# Print the subsets:
resp1000_smk
first30_ht
A little more on subsetting
# The cdc data frame is already loaded into the workspace
str(cdc)
# Create the subsets:
very_good <- subset(cdc, genhlth =="very good") # 조건으로 부분집합을 만든다
age_gt50 <- subset(cdc, age > 50) # 조건으로 부분집합을 만든다
# subset(dataframe, column ==,>= "") -> 조건에 맞는 부분집합을 추출
# Print the subsets:
head(very_good)
dim(very_good)[1] # 2만중 6972개
head(age_gt50)
dim(age_gt50)[1] # 2만중 6938개
Subset - one last time
# The cdc data frame is already loaded into the workspace
# Create the subset:
under23_and_smoke <- subset(cdc, age < 23 & smoke100 == 1) # == 조심
# Print the top six rows of the subset:
head(under23_and_smoke)
Visualizing with box plots
# The cdc data frame is already loaded into the workspace.
# Draw the box plot of the respondents heights:
boxplot(cdc$height)
# Print the summary:
summary(cdc$height)
# 최소 - 1/4th - 평균 - 3/4th - 최대
More on box plots
# This notation is new. The ~ operator can be read “versus” or “as a function of”.
# The cdc data frame is already loaded into the workspace.
# Draw the box plot of the weights versus smoking:
boxplot(cdc$weight ~ cdc$smoke100) # 담배를 x축으로 사용한 경우
# boxplot은 numerical data의 분포에 사용
# ~ 를 통해서 타 범주 구분에 따라 나누어 볼수 있다
One last box plot
# The cdc data frame is already loaded into the workspace.
# Calculate the BMI:
bmi <- cdc$weight /(cdc$height^2) * 703.0
# Draw the box plot:
boxplot(bmi ~ cdc$genhlth) # 건강상태에 따른 BMI 분포를 표시
Histograms
# The cdc data frame and bmi object are already loaded into the workspace.
# Draw a histogram of bmi:
hist(bmi)
# And one with breaks set to 50:
hist(bmi, breaks=50)
# And one with breaks set to 100:
hist(bmi, breaks=100)
# breaks는 구간의 갯수, bin의 개수
Weight vs. Desired Weight
# The cdc data frame is already loaded into the workspace.
# Draw your plot here:
plot(cdc$weight ~ cdc$wtdesire) # 관계를 표시할때는 y ~ x