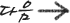7. K-Means
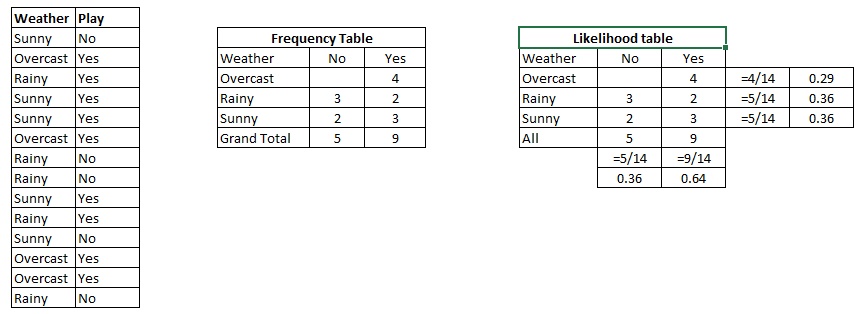
It is a type of unsupervised algorithm which solves the clustering problem. Its procedure follows a simple and easy way to classify a given data set through a certain number of clusters (assume k clusters). Data points inside a cluster are homogeneous and heterogeneous to peer groups.
Remember figuring out shapes from ink blots? k means is somewhat similar this activity. You look at the shape and spread to decipher how many different clusters / population are present!

How K-means forms cluster:
- K-means picks k number of points for each cluster known as centroids. (K개의 중심점을 찍는다.)
- Each data point forms a cluster with the closest centroids i.e. k clusters. (각 Data Point 를 중심점으로 묶는다)
- Finds the centroid of each cluster based on existing cluster members. Here we have new centroids. (각 cluster별로 새로운 중심점을 잡는다)
- As we have new centroids, repeat step 2 and 3. Find the closest distance for each data point from new centroids and get associated with new k-clusters. Repeat this process until convergence occurs i.e. centroids does not change.
(위의 2,3번을 중심점이 변하지 않을때까지 반복한다)
How to determine value of K:
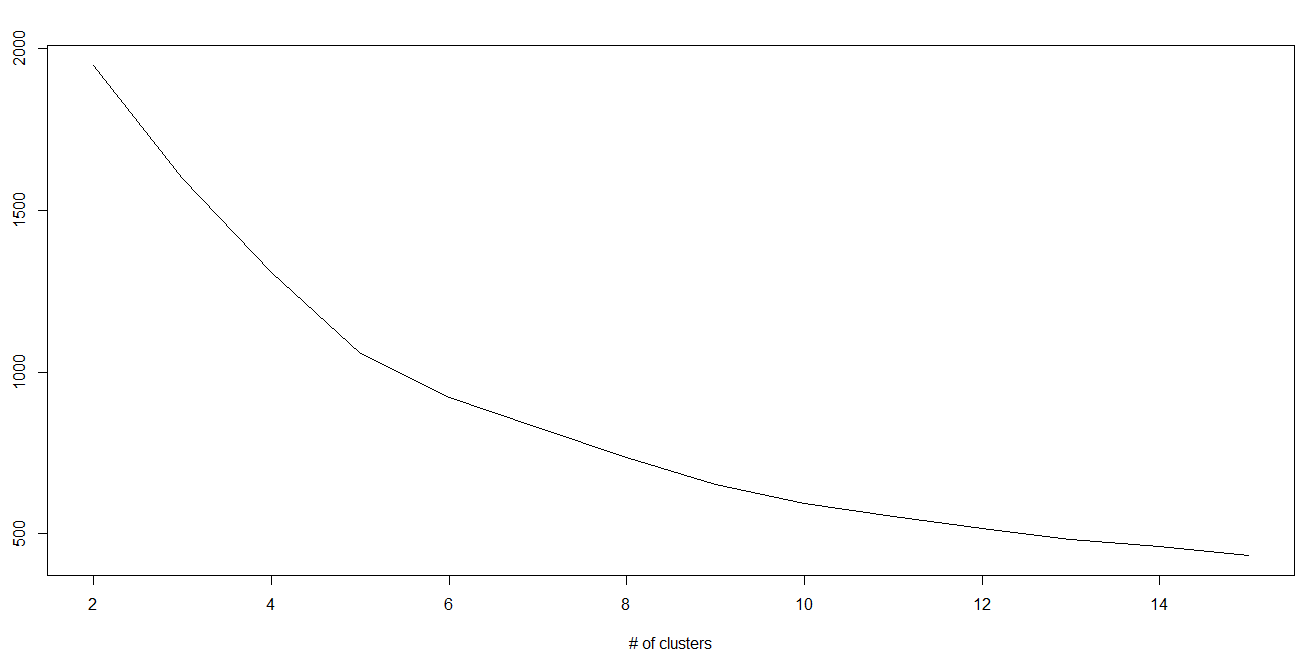
In K-means, we have clusters and each cluster has its own centroid. Sum of square of difference between centroid and the data points within a cluster constitutes within sum of square value for that cluster. Also, when the sum of square values for all the clusters are added, it becomes total within sum of square value for the cluster solution.
중심점과 그 cluster내 datapoint 사이의 거리제곱근합은 중심점의 갯수가 늘어갈 수록 적어진다. 즉, 동일 cluster내 중심점과 유사성은 점점 커진다.
= 고객 세그먼트를 잘게 나눌수록 그 세그먼트 대표 profile(= 중심점)과 data point는 점점 유사해 진다.
We know that as the number of cluster increases, this value keeps on decreasing but if you plot the result you may see that the sum of squared distance decreases sharply up to some value of k, and then much more slowly after that. Here, we can find the optimum number of cluster.
Python Code
#Import Library from sklearn.cluster import KMeans #Assumed you have, X (attributes) for training data set and x_test(attributes) of test_dataset # Create KNeighbors classifier object model k_means = KMeans(n_clusters=3, random_state=0) # Train the model using the training sets and check score model.fit(X) #Predict Output predicted= model.predict(x_test)
R Code
library(cluster) fit <- kmeans(X, 3) # 3 cluster solution # 3개의 중심점을 만들어 시작한다.
8. Random Forest 랜덤 포레스트
Random Forest is a trademark term for an ensemble of decision trees. In Random Forest, we’ve collection of decision trees (so known as “Forest”). To classify a new object based on attributes, each tree gives a classification and we say the tree “votes” for that class. The forest chooses the classification having the most votes (over all the trees in the forest).
의사결정나무 여러개의 집합을 만들어 숲이라 부른다. 새로운 값을 분류(classification) 하고자 할때 각각의 나무에게 투표권을 주어서 가장 많은 나무로 부터 득표한 class에 할당한다.
Each tree is planted & grown as follows:
- If the number of cases in the training set is N, then sample of N cases is taken at random but with replacement. This sample will be the training set for growing the tree.
훈련셋에서 일부를 복원 추출법으로 추출한다 - If there are M input variables, a number m<<M is specified such that at each node, m variables are selected at random out of the M and the best split on these m is used to split the node. The value of m is held constant during the forest growing.
입력변수가 모두 M개일때 그중 m개를 무작위로 뽑아서 Decision Tree만드는 방식으로 분기노드를 만든다 - Each tree is grown to the largest extent possible. There is no pruning. 가지치기는 없다.
For more details on this algorithm, comparing with decision tree and tuning model parameters, I would suggest you to read these articles:
Python
#Import Library from sklearn.ensemble import RandomForestClassifier #Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset # Create Random Forest object model= RandomForestClassifier() # Train the model using the training sets and check score model.fit(X, y) #Predict Output predicted= model.predict(x_test)
R Code
library(randomForest) x <- cbind(x_train,y_train) # Fitting model fit <- randomForest(Species ~ ., x,ntree=500) # 트리를 500개 만든다는 뜻 summary(fit) #Predict Output predicted= predict(fit,x_test)