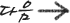2015. 9. 27. 17:55
데이터마이닝 05-문서필터링
- (p4) 스팸 필터링 : 규칙 기반 필터링
- 규칙 기반 필터링 방법
- 메시지 헤더나 본문의 내용/생김새 관찰 , 미리 정의한 규칙에 따라 스팸 여부 결정
- 예 – Outlook의 정크메일 필터 – Procmail
- 문제점
- 변화하는 스팸을 잡기 위해 끊임없이 새 규칙 추가 부담 , 스패머들이 규칙 파악 후 스팸 형태를 바꾸기 쉬움
- 스팸만을 거르기 위한 알맞은 규칙을 만들기 어려움, 너무 강한 규칙으로 햄까지 걸러낼 위험
- (P9) 스팸 필터링 : 확률 통계 기반 필터링
- Bayes’ Theorem 예제(2)
- 불량 노트북 공장 예
- 두개의 노트북 조립라인을 가진 공장에서 생산된 1000대씩의 노트북들을 같은 화물 창고에 쌓아 놓았다. 각각의 조립라인을 정밀하게 조사하여, 1번 조립라인에서 생산된 노트북의 10%가 불량이고, 2번 조립라인에서 생산된 노트북의 15%가 불량임을 알았다. 화물 창고의 노트북을 하나꺼내 조사한 결과 불량이었을 때, 이 노트북이 1번 조립라인에서 생산되었을 확률은?
- (p10) 스팸 필터링: 확률 통계 기반 필터링
- 스팸 필터링의 기본 개념
- 스팸/햄으로 분류한 메시지의 단어 출현 빈도 미리 계산
- Spam으로 분류된 문서들 중 “Python”이라는 단어가 20%에서 출연
- P(Python | Spam) =0.2
- Spam으로 분류된 문서들 중 “Casino”이라는 단어가 40%에서 출연
- P( Casino | Spam) =0.4
- Spam으로 분류된 문서들 중 “Python”과 “Casino”가 동시에 출연할 확률
- P( Python & Casino | Spam ) = 0.2 * 0.4 = 0.08
- (p12) 문서와 단어: 텍스트에서 단어를 추출
- 소문자로 변환하여 반환 – 스팸에서 사용되는 SHOUTING style 메일을 놓칠수 있음
- 특성 단어를 어떻게 정의할 것인가
- (p13) 분류기 훈련시키기
- (p17) 확률 계산 - 분류별 특성의 확률
- 조건부 확률
- P(python|spam) = 분류별 메시지 출현횟수/전체 분류내의 문서 수
- 실행 def fprob(self,f,cat): if self.catcount(cat)==0: return 0 #
- 해당 분류에서 특성이 나타난 횟수를 그 분류에 있는 전체 항목 개수로 나눔
- (p18) 확률 계산 : 적당히 추정하기
- 가장 확률(assumed probability)
- 특정 단어의 빈도수가 낮아, 그 단어만으로 특정 분류에 속할 확률을 특정할 수 없음
- 예 : money라는 단어가 전체 문서들중에 ‘bad’ 문서에 딱 한번 출현
- 이 구현에서는 0.5로 시작 – 가중치 1은 한 단어와 동일한 가중치로 취급
'Machine Learning & Data Mining' 카테고리의 다른 글
| 데이터마이닝 07-고급 분류 기법-커널 기법과 svm-01 from Kwang Woo NAM (0) | 2015.09.27 |
|---|---|
| 데이터마이닝 06-의사결정트리-01 from Kwang Woo NAM (0) | 2015.09.27 |
| 데이터마이닝 04-검색과 랭킹-02 from Kwang Woo NAM (0) | 2015.09.27 |
| 데이터마이닝 03-군집발견-03 from Kwang Woo NAM (0) | 2015.09.27 |
| 데이터마이닝 02-추천시스템 만들기 from Kwang Woo NAM (0) | 2015.09.27 |